[Book summary] Hacking Growth: How Today̵
Phần 1: Thu hút khách hàng Tiền đề: Xác đ�...
Curiosity builds lifelong learning.
Bài luận văn này nhằm mục đích khám phá liệu các mô hình ngôn ngữ lớn (LLMs) có mã hóa nhiều kiến thức thực tế trong các tham số nội bộ của chúng hơn so với những gì chúng diễn đạt thông qua đầu ra văn bản hay không.
Trước tiên, các tác giả đề xuất một khung định nghĩa mới về kiến thức: Đối với một câu hỏi, mức độ kiến thức của mô hình được thể hiện qua việc nó có thể xếp hạng câu trả lời đúng trước các câu trả lời sai ở mức độ nào. Dựa trên cơ sở này, họ phân biệt giữa “Kiến thức bên ngoài” (External Knowledge) — vốn phụ thuộc vào xác suất đầu ra của mô hình, và “Kiến thức bên trong” (Internal Knowledge) — vốn tận dụng các tính toán nội bộ của mô hình (như các trạng thái ẩn). Khi kiến thức bên trong vượt xa kiến thức bên ngoài một cách đáng kể, thì tồn tại “Kiến thức ẩn” (Hidden Knowledge).
Thông qua các thí nghiệm trả lời câu hỏi kín (Closed-book QA) trên ba LLM mã nguồn mở phổ biến (Llama-3-8B, Mistral-7B, Gemma-2-9B), nghiên cứu phát hiện ra rằng các LLM phổ biến tồn tại kiến thức ẩn (với khoảng cách tương đối trung bình đạt mức 40%). Đáng ngạc nhiên hơn, đôi khi nội bộ mô hình “hoàn toàn biết” câu trả lời đúng (có khả năng xếp nó trên tất cả các câu trả lời sai), nhưng trong một lượng lớn mẫu thử (1000 lần), nó hầu như không bao giờ tạo ra câu trả lời này. Điều này tiết lộ những hạn chế trong khả năng tạo (generation) của các LLM hiện tại, đồng thời hạn chế tiềm năng của việc nâng cao hiệu suất trả lời câu hỏi thông qua việc tăng cường tính toán trong thời gian kiểm tra (chẳng hạn như lấy mẫu nhiều lần).
Paper: Inside-Out: Hidden Factual Knowledge in LLMs – arXiv:2503.15299
| Phân loại | Phương pháp nghiên cứu chính | Đóng góp/Đặc điểm chính | Hạn chế | Văn bản tiêu biểu |
| Phương pháp sớm |
1. Điền vào chỗ trống (Cloze Sentence) 2. Đặt câu hỏi trực tiếp (Zero-shot/Fine-tuning) |
– Đánh giá kiến thức thông qua việc hoàn thành câu hoặc hỏi đáp trực tiếp. – Đặt nền móng cho việc đánh giá kiến thức của LLM. |
– Phụ thuộc vào một kết quả tạo duy nhất. – Chưa xem xét tính nhất quán về ngữ nghĩa hoặc trạng thái nội bộ. |
Petroni et al., 2019; Radford et al., 2019; Roberts et al., 2020 |
| Phương pháp hiện đại | Hỏi đáp trực tiếp của LLM theo tuân thủ chỉ dẫn (Instruction-following) |
– Gần gũi hơn với các kịch bản ứng dụng thực tế. – Tận dụng khả năng hiểu chỉ dẫn của LLM. |
– Vẫn phụ thuộc vào đầu ra đơn lẻ. – Dễ bị ảnh hưởng bởi chiến lược giải mã và lời nhắc (prompt). |
Wei et al., 2024 |
| Nghiên cứu nâng cao |
1. Đánh giá tính nhất quán của các câu hỏi tương đương về ngữ nghĩa. 2. Thăm dò trạng thái nội bộ (Probing). 3. Lời nhắc tự xác thực (Self-verification Prompting). 4. Nghiên cứu chỉnh sửa và quên kiến thức. |
– Đánh giá tính cứng cáp (robustness) qua các cách diễn đạt câu hỏi khác nhau. – Tiết lộ mối quan hệ giữa trạng thái nội bộ và kiến thức. – Nâng cao độ tin cậy thông qua hiệu chuẩn mức độ tự tin. – Khám phá tác động của việc cập nhật kiến thức động. |
– Tính khả giải của phương pháp thăm dò còn hạn chế. – Thiết kế lời nhắc phụ thuộc vào kinh nghiệm thủ công. – Hiệu quả lâu dài của chỉnh sửa kiến thức chưa rõ ràng. |
Elazar et al., 2021; Burns et al., 2023; Azaria & Mitchell, 2023; Lin et al., 2022; Kadavath et al., 2022; Cohen et al., 2024; Gekhman et al., 2024 |
Tổng kết những thiếu sót của các nghiên cứu trước đây:
Vấn đề của các phương pháp truyền thống: Trước đây, việc đánh giá liệu một LLM có “biết” một sự thật hay không (ví dụ: “Thủ đô của Pháp là Paris”) thường chỉ dựa vào việc nó có thể tạo ra câu trả lời đúng hay không. Tuy nhiên, cách tiếp cận này sẽ bỏ qua các trường hợp:
Định nghĩa mới: Kiến thức = Khả năng phân biệt giữa câu trả lời đúng và các câu trả lời gây nhiễu.
Biểu đạt toán học:
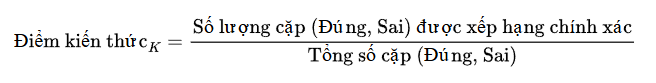
Cách tiếp cận này giống như các câu hỏi trắc nghiệm trong một kỳ thi — một “học bá” thực thụ không chỉ có thể chọn đúng đáp án, mà còn có thể loại trừ một cách rõ ràng tất cả các phương án sai.
| Loại | Nguồn dữ liệu | Phương pháp ví dụ | Đặc điểm |
| Kiến thức bên ngoài | Chỉ sử dụng các tín hiệu đầu ra có thể quan sát được, chủ yếu dựa trên tính toán xác suất của các Token. | – Xác suất tạo P(a|q) – Tự xác thực: P(True|q,a) |
Do hạn chế của chiến lược giải mã, lượng kiến thức thực sự có thể bị đánh giá thấp. |
| Kiến thức bên trong | Có thể tận dụng quá trình tính toán trung gian của mô hình, ví dụ như trạng thái ẩn của các lớp. | Thăm dò tuyến tính (Linear Probing) phân tích mô hình kích hoạt của lớp ẩn. | Tiết lộ kiến thức tiềm năng trong “quá trình suy nghĩ” của mô hình. |
Khi Điểm kiến thức bên trong >> Điểm kiến thức bên ngoài, điều đó chứng minh sự tồn tại của Kiến thức ẩn (mô hình biết nhưng không nói ra được).
Thiết kế này đánh giá toàn diện hơn năng lực nhận thức thực sự của mô hình, thay vì chỉ tập trung vào kết quả đầu ra.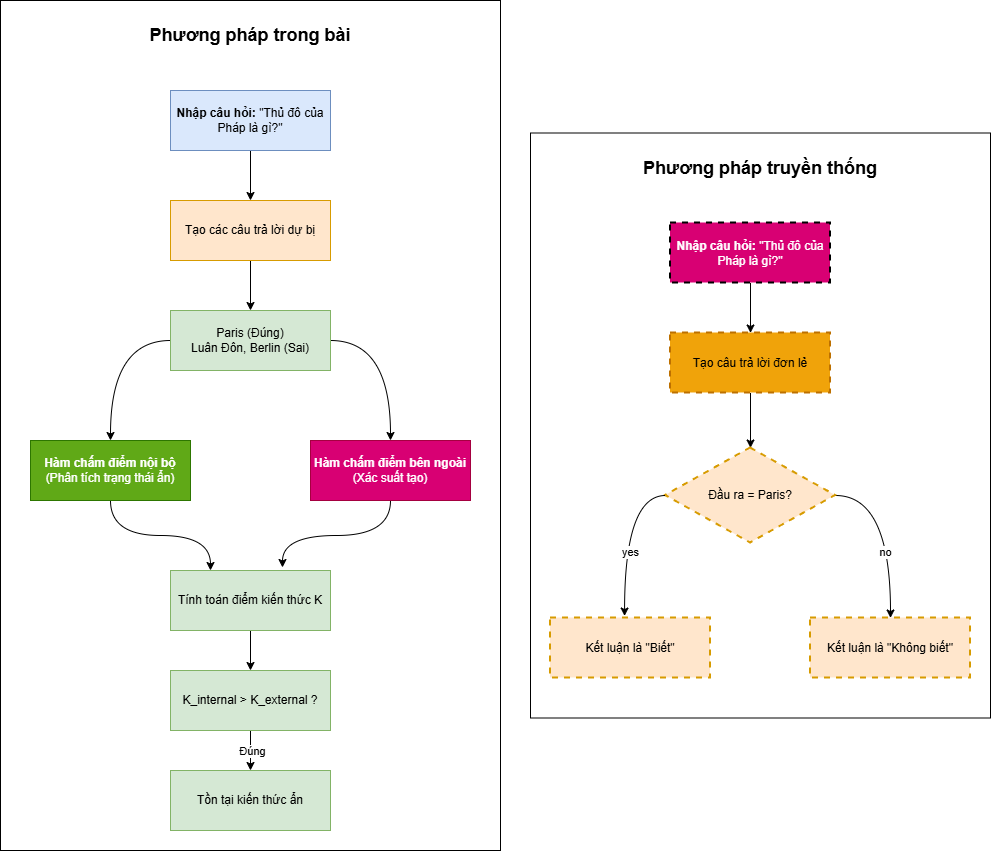
Phân tích sự khác biệt chính:
Sơ đồ này minh họa trực quan cho hiện tượng “biểu lý bất nhất” mà chúng ta đã thảo luận: AI có thể sở hữu kiến thức trong “não bộ” (trạng thái ẩn) nhưng lại không thể diễn đạt ra “miệng” (xác suất tạo).
Để xác thực tư tưởng cốt lõi, các tác giả đã thiếtkế một bộ quy trình thực nghiệm để tính toán và so sánh một cách xấp xỉ giữa kiến thức nội bộ và kiến thức bên ngoài.
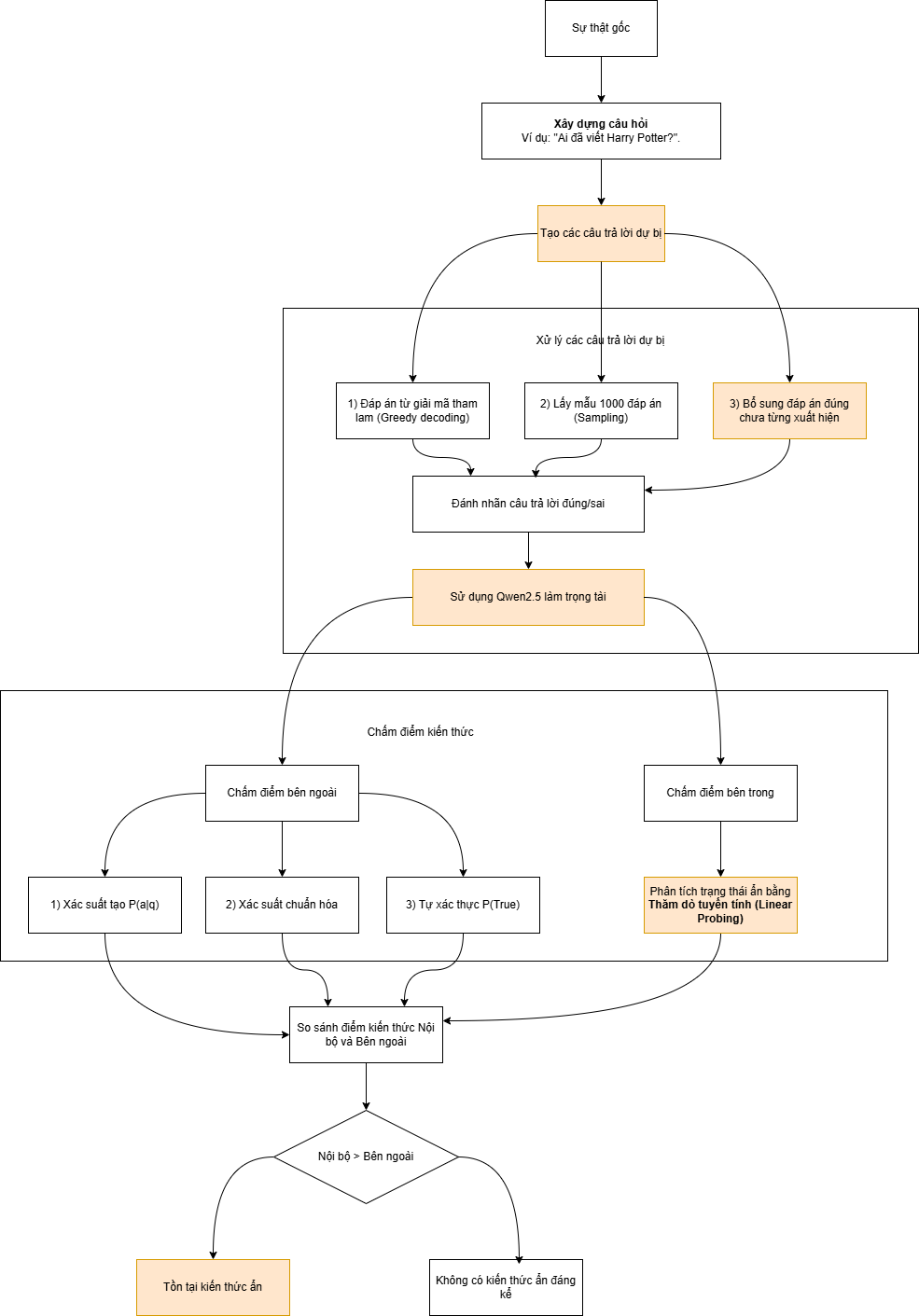
| Loại | Tên/Phương pháp | Mô tả | Mục đích/Chỉ số đo lường |
| Hàm chấm điểm bên ngoài | P(a|q) | Tích xác suất của các token gốc tạo nên câu trả lời a. | Đo lường xác suất mô hình sẽ đưa ra câu trả lời ‘a’. |
| P\_norm(a|q) | Độ dài được chuẩn hóa của P(a|q) | Tránh việc xác suất của câu trả lời dài bị thấp do độ dài. | |
| P(True|q,a) | Thông qua các lời nhắc (prompt) đặc biệt để mô hình tự phán đoán xem $a$ có phải là câu trả lời đúng cho $q$ hay không, và quan sát xác suất mô hình tạo ra từ “True”. |
Đo lường năng lực xác thực (Verification) của mô hình, tức là khả năng phán đoán xem một câu trả lời là đúng hay sai. |
|
| Hàm chấm điểm bên trong | Bộ phân loại thăm dò (Probing Classifier) |
1. Trích xuất trạng thái ẩn h_M(q,a) sau khi đưa câu hỏi q và câu trả lời ứng viên a vào mô hình M. 2. Sử dụng bộ phân loại tuyến tính (Logistic Regression) để dự đoán xem a có đúng với q hay không. 3. Xác suất của lớp “Đúng” do bộ phân loại đưa ra được dùng làm điểm số nội bộ T_M(q,a). |
Đo lường mức độ tin cậy nội bộ của mô hình đối với câu trả lời a. Thông qua phân tích trạng thái ẩn để suy luận xem mô hình có “biết” một câu trả lời là đúng hay không. Sử dụng chiến lược “Thăm dò nhận biết kiến thức” (Knowledge-aware Probing) tập trung vào việc phân biệt đáp án đúng và sai của các sự thật đã biết. |
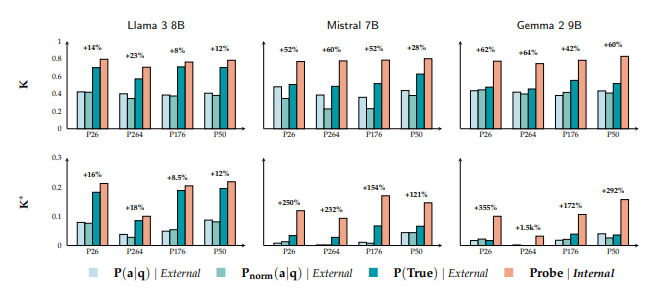
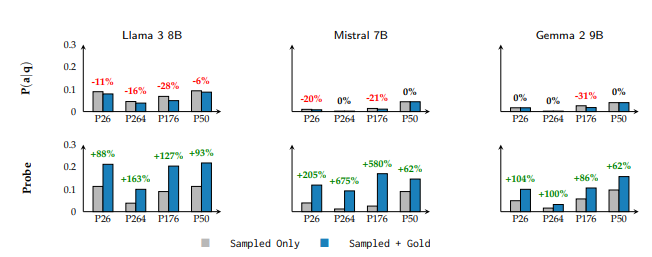
Thiết kế thí nghiệm: Đối với ba mô hình Llama-3-8B, Mistral-7B, và Gemma-2-9B, trên khoảng 1700 câu hỏi kiểm thử thuộc 4 loại quan hệ, các tác giả đã tiến hành so sánh điểm kiến thức nội bộ $K_{int}$ (tính bằng bộ thăm dò) và ba loại điểm kiến thức bên ngoài K_{ext} (tính từ P, P_norm, P_true). Chỉ số K=1 đại diện cho khả năng phân biệt hoàn hảo giữa tất cả các cặp đáp án đúng và sai.
Kết quả chính:
| Phân loại | Dữ liệu then chốt | Phát hiện cốt lõi | Giải mã ý nghĩa | Minh họa bằng ẩn dụ |
| Tính phổ biến của kiến thức ẩn | Cả 3 mô hình × 4 quan hệ đều có sự chênh lệch đáng kể. Cách biệt trung bình đạt 40%. | Tất cả các LLM đều tồn tại tình trạng: Kiến thức nội bộ > Diễn đạt bên ngoài. | Chứng minh “biết nhưng không nói ra được” là hiện tượng phổ biến ở LLM. | Giống như học sinh hiểu bài trong lòng nhưng khi đi thi lại phát huy không tốt. |
| Sự khác biệt giữa các mô hình | Gemma 57% so với Llama 14%. | Các kiến trúc/huấn luyện khác nhau dẫn đến khả năng bộc lộ kiến thức khác nhau. | Gemma có khả năng diễn đạt kiến thức yếu nhất, Llama mạnh nhất. | Giống như sự khác biệt về khả năng diễn đạt giữa những người có tính cách khác nhau. |
| Năng lực Xác thực vs. Tạo nội dung | P(True) > P(a||q) ở tất cả các thử nghiệm. | Mô hình giỏi việc xác thực đáp án hơn là tự tạo ra đáp án. | Hỏi trực tiếp “đúng hay sai” đáng tin cậy hơn là nhìn vào xác suất tạo đáp án. | Giống như việc con người giỏi chấm bài tập hơn là tự viết bản thảo gốc. |
| Trường hợp ẩn giấu cực đoan | 9% số câu hỏi xuất hiện trạng thái K*=1 nhưng tỷ lệ tạo đáp án bằng 0. | Mô hình nắm vững hoàn toàn kiến thức nhưng không thể tạo ra đáp án đúng. | Tiết lộ cơ chế tạo nội dung (generation) tồn tại những nút thắt cổ chai căn bản. | Biểu hiện cực đoan của hiện tượng “đầu lưỡi” (biết nhưng không nhớ ra từ). |
| Hạn chế từ nút thắt tạo nội dung | Việc bổ sung các đáp án chưa được tạo ra giúp tăng 40% độ chính xác. | Ngưỡng hiệu suất tối đa bị hạn chế bởi tỷ lệ bao phủ của việc tạo đáp án. | Các thuật toán giải mã hiện tại không thể trích xuất hiệu quả toàn bộ kiến thức. | Giống như thư viện có sách nhưng hệ thống tra cứu lại không hoàn thiện. |
Kết luận
Các LLM phổ biến tồn tại Kiến thức ẩn, nghĩa là kiến thức được mã hóa nội bộ của chúng nhiều hơn so với kiến thức biểu đạt ra bên ngoài. Cơ chế tạo (giải mã) của LLM hiện tại tồn tại những hạn chế, đôi khi thậm chí không thể tạo ra câu trả lời mà nội bộ mô hình đã nắm vững hoàn toàn. Sự hạn chế trong khả năng tạo này là một yếu tố quan trọng kìm hãm việc nâng cao hiệu suất trả lời câu hỏi kín (Closed-book QA) thông qua việc tăng cường lấy mẫu và xếp hạng trong thời gian kiểm tra. Khung định nghĩa và đánh giá kiến thức do các tác giả đề xuất đã cung cấp nền tảng cho các nghiên cứu tương lai về kiến thức ẩn và cải thiện hiệu quả sử dụng kiến thức của mô hình.
| Loại hạn chế | Biểu hiện cụ thể | Tác động tiềm tàng | Hướng cải thiện |
| Hạn chế tài nguyên tính toán | Chỉ thử nghiệm mô hình 7B-9B; lấy mẫu 1000 lần/câu hỏi. | Chưa thể xác thực quy luật trên các mô hình lớn hơn. | Phát triển các phương pháp đánh giá tinh gọn. |
| Hạn chế định nghĩa kiến thức | Đánh giá sự thật đơn lẻ; bỏ qua kiến thức liên quan. | Có thể đánh giá thấp mức độ kiến thức tổng thể. | Xây dựng đánh giá dạng đồ thị tri thức. |
| Tính nhạy cảm của nhãn | K* phụ thuộc vào việc dán nhãn hoàn hảo; LLM Judge có thể sai. | Các phán đoán trong trường hợp cực đoan có thể bị nghi ngờ. | Cơ chế bỏ phiếu với nhiều trọng tài. |
| Hạn chế phương pháp luận | Chiều đánh giá đơn nhất: Mỗi sự thật chỉ có 1 cách diễn đạt câu hỏi. | Bỏ qua tính nhạy cảm với lời nhắc (prompt). | Tăng tính đa dạng của câu hỏi. |
| Tính đơn giản của bộ thăm dò: Chỉ dùng bộ phân loại tuyến tính. | Có thể bỏ sót các đặc trưng phi tuyến tính. | Đưa vào các bộ thăm dò phi tuyến tính. | |
| Rủi ro giả định huấn luyện: Giả định “Tham lam đúng = Biết”. | Bộ thăm dò có thể tạo ra sai lệch. | Xác minh kiến thức đa chiều. | |
| Thách thức tính tổng quát | Loại quan hệ hạn chế: Chỉ thử nghiệm 4 loại quan hệ thực thể. | Khả năng áp dụng cho các loại kiến thức khác còn bỏ ngỏ. | Mở rộng tính đa dạng của các quan hệ. |
| Hạn chế của mô hình phán quyết: Qwen2.5 làm trọng tài có giới hạn về chất lượng. | Chất lượng phán quyết có ngưỡng tối đa. | Sử dụng chuyên gia con người để kiểm tra lại. |
Mô hình có thể lưu trữ kiến thức hoàn hảo trong các trạng thái ẩn nội bộ, nhưng cơ chế giải mã (decoding) hiện tại lại là một “nút thắt cổ chai”. Điều này tạo ra nghịch lý: AI càng thông minh thì khoảng cách giữa những gì nó “biết” và những gì nó “nói ra” có thể càng lớn nếu công nghệ giải mã không bắt kịp.
Việc tăng cường lấy mẫu (Sampling) có thể giúp tìm ra đáp án đúng (tăng hiệu suất), nhưng nghiên cứu cho thấy ngay cả khi lấy mẫu 1000 lần, AI vẫn có thể trượt mất đáp án mà nó vốn đã biết. Điều này đặt ra câu hỏi: Liệu chúng ta nên tin vào kết quả văn bản (External) hay tin vào “trực giác” nội bộ (Internal) của mô hình?
Để hiểu sâu về AI (Tính khả giải), chúng ta cần các phương pháp phức tạp như thăm dò tuyến tính (Probing). Tuy nhiên, để ứng dụng thực tế (Tính thực dụng), người dùng chỉ cần một câu trả lời nhanh và chính xác. Việc thu hẹp khoảng cách này đòi hỏi sự đánh đổi về tài nguyên tính toán (như hình ảnh bạn đã gửi).
Sự tồn tại của “Kiến thức ẩn” là một con dao hai lưỡi. Một mặt, nó là kho tàng tiềm năng chưa khai phá. Mặt khác, nó tiềm ẩn rủi ro: Mô hình có thể “giấu” những kiến thức nguy hiểm hoặc nhạy cảm mà chúng ta không thể kiểm soát hết chỉ bằng cách quan sát các câu trả lời thông thường.
Kiến thức ẩn xảy ra khi: Suy nghĩ nội tâm của một người (kiến thức bên trong) cho thấy họ thực sự hiểu vấn đề, nhưng lời nói ra (kiến thức bên ngoài) lại không rõ ràng hoặc thậm chí nói sai.
“Thăm dò” (Probe) là một kỹ thuật phổ biến trong lĩnh vực tính khả giải của học máy, có thể tưởng tượng nó như một “thiết bị đọc” hay “cảm biến” siêu nhỏ.
Ví dụ: Giống như bác sĩ dùng ống nghe (bộ thăm dò) để nghe tiếng tim (trạng thái ẩn) nhằm phán đoán trái tim có khỏe không (đáp án đúng hay sai), ngay cả khi vẻ ngoài của bệnh nhân (đầu ra bên ngoài) trông có vẻ bình thường.
Điều này tiết lộ hố ngăn sâu hoắm giữa việc mã hóa kiến thức nội bộ và quá trình tạo ra văn bản bên ngoài. Các nguyên nhân bao gồm:
Có khả năng đó, đây là sự đánh đổi giữa tính mục tiêu và thiên kiến tiềm tàng.
Theo tomsheep
